爱心捐赠
centos
阿克曼
虚拟机
EPICS
图像阴影消除
产品运营
天猫
规范
业界资讯
多态和虚函数的使用底层实现原理
自媒体
滤波
前端酒店管理系统
线段树
mulesoft
BP神经网络
神经网络预测
CVE
EDI
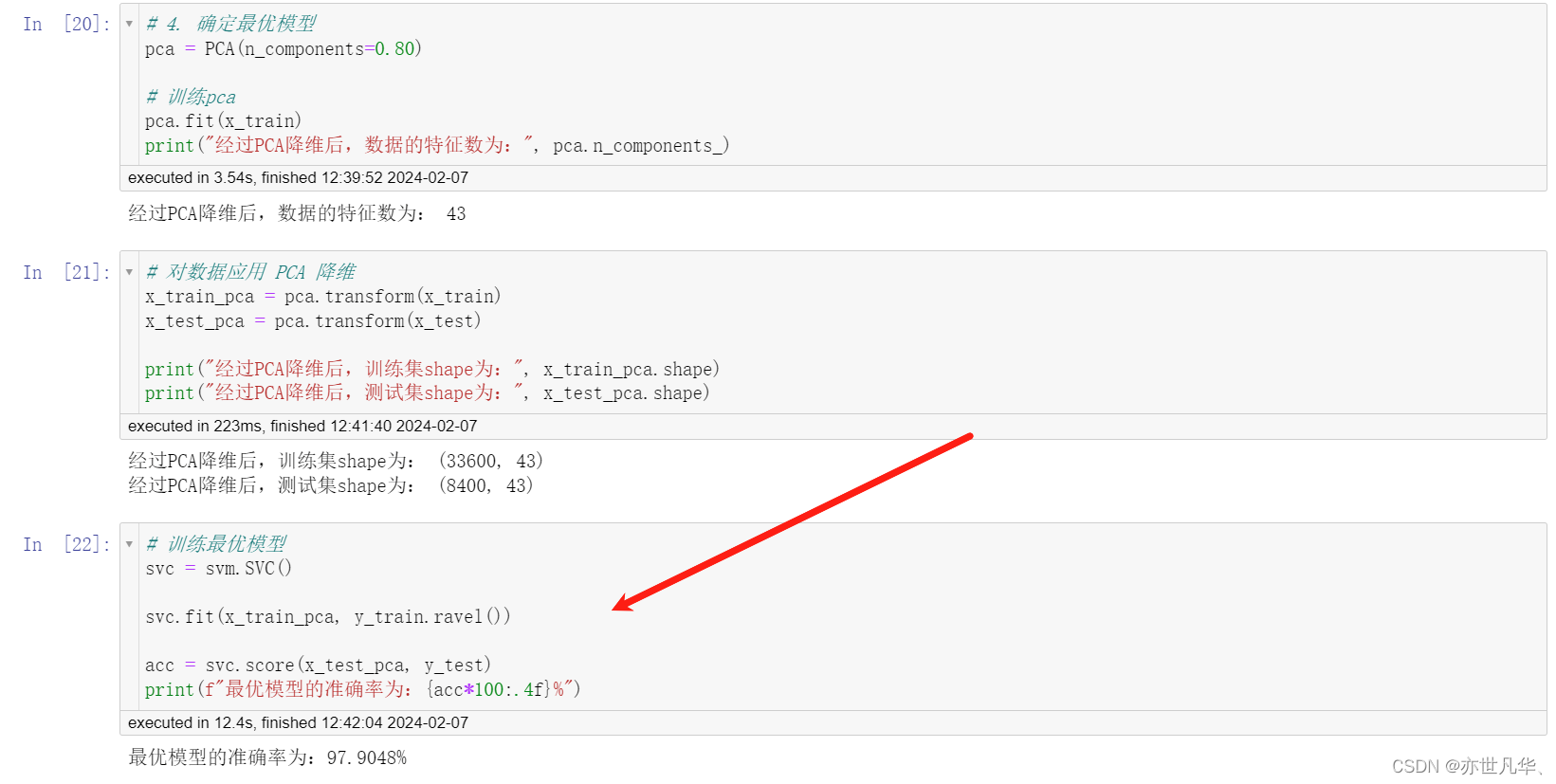
svm
2024/4/12 0:27:47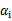
SMO优化算法(Sequential minimal optimization)
本文转载自 http://www.cnblogs.com/jerrylead/archive/2011/03/18/1988419.html。SMO算法由Microsoft Research的John C. Platt在1998年提出,并成为最快的二次规划优化算法,特别针对线性SVM和数据稀疏时性能更优。关于SMO最好的资料就是他本人写的《Seq…
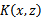
支持向量机SVM 核函数
本文转载自:https://www.cnblogs.com/jerrylead/archive/2011/03/18/1988406.html
考虑我们最初在“线性回归”中提出的问题,特征是房子的面积x,这里的x是实数,结果y是房子的价格。假设我们从样本点的分布中看到x和y符合3次曲线&a…

深入解析:svm支持向量机python代码
下面是使用 scikit-learn 库中的 SVM 模型的示例代码: from sklearn import svm
from sklearn.datasets import make_classification# generate some example data
X, y make_classification(n_features4, random_state0)# fit an SVM model to the data
clf svm.…

查准率与查全率在自然语言处理中的核心概念与联系、核心概念和实践应用,如何使用朴素贝叶斯、SVM 和深度学习实现查准率和查全率的计算?
查准率与查全率在自然语言处理中的核心概念与联系、核心概念和实践应用,如何使用朴素贝叶斯、SVM 和深度学习实现查准率和查全率的计算? 人工智能核心技术有:1. 深度学习;2.计算机视觉;3.自然语言处理;4.数据挖掘。其中,深度学习就是使用算法分析数据,从中学习并自动归…
支持向量机(Support Vector Machine,SVM)算法 简介
支持向量机(Support Vector Machine,SVM)算法,简称SVM 算法。
在保证了分类正确性的同时,还尽可能让两个样本的类别更容易区分。简单来说就是,不仅做对了,还保证了质量。
当样本数据是线性可分…
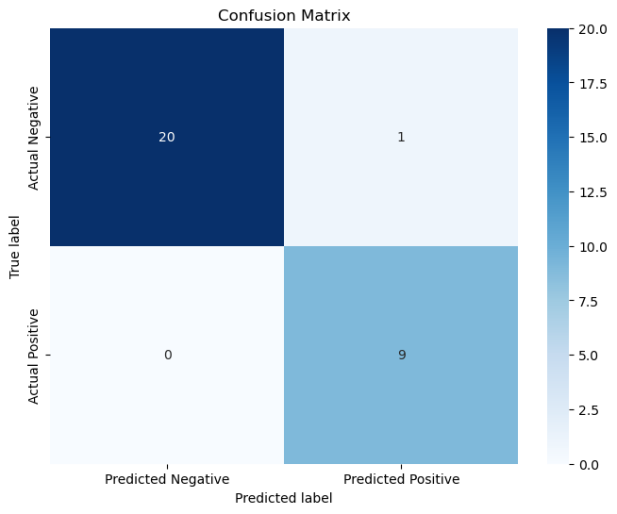
机器学习实验3——支持向量机分类鸢尾花
文章目录 🧡🧡实验内容🧡🧡🧡🧡数据预处理🧡🧡代码认识数据相关性分析径向可视化各个特征之间的关系图 🧡🧡支持向量机SVM求解🧡🧡直觉…
LIBSVM入门笔记(matlab2013a+VS2013)
一、下载libsvm LIBSVM是台湾大学林智仁(Lin Chih-Jen)教授等开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包,在http://www.csie.ntu.edu.tw/~cjlin/libsvm/可以下载,目前版本是libsvm-3.20,推荐把下载的libsvm-3.20.zi…

100 Days Of ML Code:Day9/10/12/14 - SVM(支持向量机)
100天机器学习挑战汇总文章链接在这儿。 目录
Step 1:预处理
Step 2:应用Sklearn中的SVC
Step 3:预测
Step 4:绘制结果
最后:全部代码 SVM的学习可以参考我的这两篇文章:SVM上、SVM下。
Step 1&#…
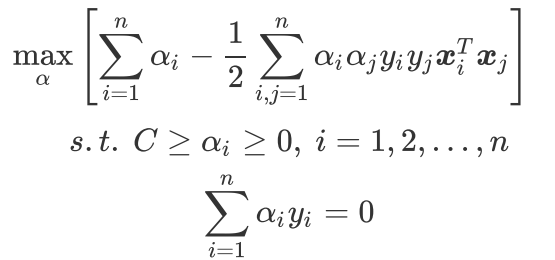
机器学习-SVM(支持向量机)
推荐课程:【机器学习实战】第5期 支持向量机 |数据分析|机器学习|算法|菊安酱_哔哩哔哩_bilibili 赞美菊神ヾ ( ゜ⅴ゜)ノ 一、什么是支持向量机? 支持向量机(Support Vector Machine, SVM)是一类按监督学习࿰…

周志华Watermelon Book SVM部分公式补充、一些原理解释
Z.F Zhou Watermelon Book SVM.This article is a supplementary material for SVM. Watermelon Book
6.3
Suppose training data set is linear separable.Minimum margin is δ\deltaδ. {wTxb>δ,yi1wTxb<−δ,yi−1→{wTδxbδ>1,yi1wTδxbδ<−1,yi−1\begi…

机器学习之线性支持向量机(机器学习技法)
胖的就是好的(以二元分类为例)
直觉的选择
现在我们已经能够分割线性的资料了,但是由于以前的算法(PLA,Pocket,etc.)具有一些随机性所以我们得到的线性模型不尽相同。如下图:在图中所…
【神经网络学习笔记】LIBSVM参数讲解
支持向量机SVM(Support Vector Machine)作为一种可训练的机器学习方法可以实现模式分类和非线性回归,本文就matlab中的LIBSVM工具箱展开说明。
在matlab中调用LIBSVM工具箱可以方便的使用LIBSVM网络,台湾大学的林智仁教授已经封装好各方法&…

matlab实现机器学习svm
一、目的和要求
1.编程实现SVM训练函数和预测函数;
2.绘制线性和非线性边界;
3.编写线性核函数
二、算法
1.线性svm:
分离超平面:wxb0,对于线性可分的数据集来说,这样的超平面有无穷多个(…


分类预测 | Matlab实现QPSO-SVM、PSO-SVM、SVM多特征分类预测对比
分类预测 | Matlab实现QPSO-SVM、PSO-SVM、SVM多特征分类预测对比 目录 分类预测 | Matlab实现QPSO-SVM、PSO-SVM、SVM多特征分类预测对比分类效果基本描述程序设计参考资料 分类效果 基本描述 1.Matlab实现QPSO-SVM、PSO-SVM、SVM分类预测对比,运行环境Matlab2018b…
基于OpenCV的图形分析辨认05(补充)
目录
一、前言
二、实验内容
三、实验过程 一、前言
编程语言:Python,编程软件:vscode或pycharm,必备的第三方库:OpenCV,numpy,matplotlib,os等等。
关于OpenCV,num…
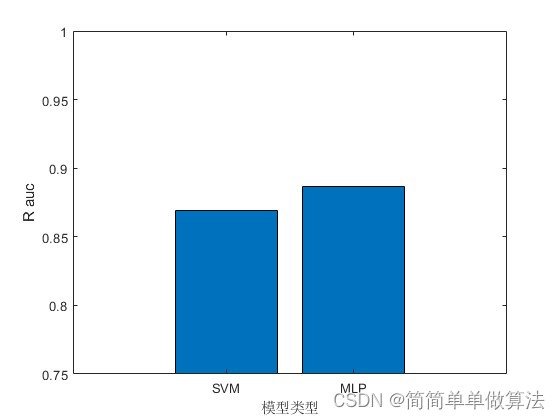
基于支持向量机SVM和MLP多层感知神经网络的数据预测matlab仿真
目录
1.算法运行效果图预览
2.算法运行软件版本
3.部分核心程序
4.算法理论概述
一、支持向量机(SVM)
二、多层感知器(MLP)
5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本
matlab2022a
3.部分核心程序
.…
GEE机器学习——利用支持向量机SVM进行土地分类和精度评定
支持向量机方法
支持向量机(Support Vector Machine,SVM)是一种常用的机器学习算法,主要用于分类和回归问题。SVM的目标是找到一个最优的超平面,将不同类别的样本点分隔开来,使得两个类别的间隔最大化。具体来说,SVM通过寻找支持向量(即距离超平面最近的样本点),确定…
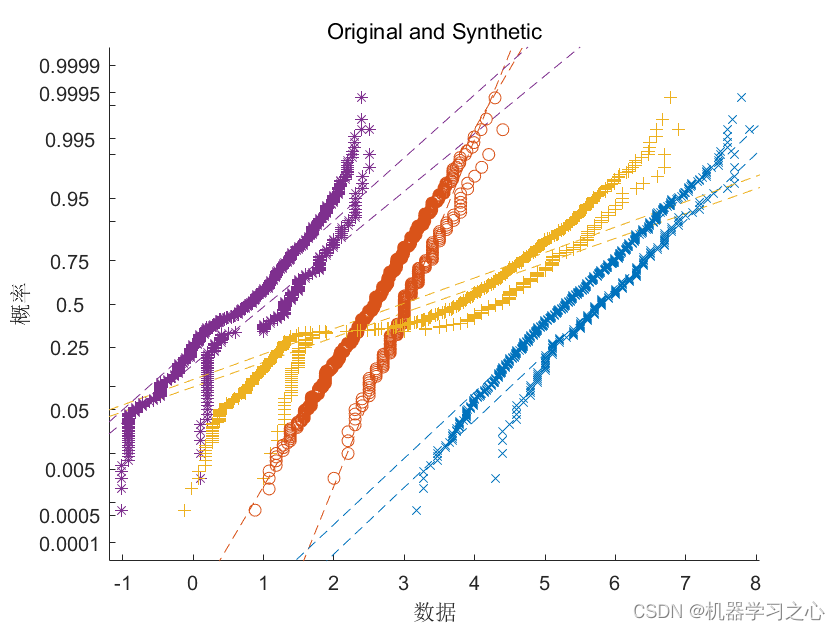
数据生成 | MATLAB实现GAN生成对抗网络结合SVM支持向量机的数据生成
数据生成 | MATLAB实现GAN生成对抗网络结合SVM支持向量机的数据生成 目录 数据生成 | MATLAB实现GAN生成对抗网络结合SVM支持向量机的数据生成生成效果基本描述程序设计参考资料 生成效果 基本描述 数据生成 | MATLAB实现GAN生成对抗网络结合SVM支持向量机的数据生成。 生成对抗…

机器学习-基于支持向量机的分类预测
一、SVM简介
1.总体框架 2.相关概念
线性可分:在二维空间上,两类点被一条直线完全分开叫做线性可分。 超平面:从二维空间扩展到多维空间时,将两两类样本完全正确的划分开来的线(上述线性可分的直线)就变成…

基于SVM+TensorFlow+Django的酒店评论打分智能推荐系统——机器学习算法应用(含python工程源码)+数据集+模型(一)
目录 前言总体设计系统整体结构图系统流程图 运行环境Python环境TensorFlow 环境方法一方法二 安装其他模块安装MySQL 数据库 模块实现1. 数据预处理1)数据整合2)文本清洗3)文本分词 相关其它博客工程源代码下载其它资料下载 前言
本项目以支…
深度学习与计算机视觉系列(4)_最优化与随机梯度下降
作者:寒小阳 && 龙心尘 时间:2015年12月。 出处: http://blog.csdn.net/han_xiaoyang/article/details/50178505 http://blog.csdn.net/longxinchen_ml/article/details/50178845 声明:版权所有,转载请联…

机器学习之核函数逻辑回归(机器学习技法)
从软间隔SVM到正则化
从参数ξ谈起
在软间隔支持向量机中参数ξ代表某一个资料点相对于边界犯错的程度,如下图:在资料点没有违反边界时ξ的值为0,在违反边界时的值就会大于0。所以总的来说ξ的值等于max(1 - y(WZ b) , 0)。所以我们把问题合…
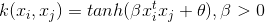
SVM支持向量机-核函数(6)
引言: 前边几篇文章中提到的分类数据点,我们都假设是线性可分的,即存在超平面将样本正确分类,然而现实生活中,存在许多线性不可分的情况,例如“异或”问题就不是线性可分的,看一下西瓜书上的一个…
机器学习_13_SVM支持向量机、感知器模型
文章目录 1 感知器模型1.1 感知器的思想1.2 感知器模型构建1.3 损失函数构建、求解 2 SVM3 线性可分SVM3.1 线性可分SVM—概念3.2 线性可分SVM —SVM 模型公式表示3.3 线性可分SVM —SVM 损失函数3.4 优化函数求解3.5 线性可分SVM—算法流程3.6 线性可分SVM—案例3.7 线性可分S…

支持向量机SVM原理(下)
本文主要基于youtube上的视频(炼数成金机器学习课程):https://www.youtube.com/watch?vCz144VkaRUQ
本文是文章支持向量机SVM原理(上)的下篇。
目录
1 线性不可分系统的SVM
2 对偶问题的解法
3 映射到高位空间 1…

SVM入门(八)至(九)松弛变量
原文链接:http://www.blogjava.net/zhenandaci/archive/2009/03/15/259786.html
http://www.blogjava.net/zhenandaci/archive/2009/03/17/260315.html现在我们已经把一个本来线性不可分的文本分类问题,通过映射到高维空间而变成了线性可分的。就像下图这…

SVM入门(一)至(三)Refresh
原文地址:
http://www.blogjava.net/zhenandaci/archive/2009/02/13/254519.html(一)SVM的八股简介支持向量机(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解决小样本、非线性及高维模式识别中表现出许多特有…

SVM入门(四)至(六)线性分类器的求解
原文链接
http://www.blogjava.net/zhenandaci/archive/2009/02/13/254578.html
http://www.blogjava.net/zhenandaci/archive/2009/02/14/254630.html
http://www.blogjava.net/zhenandaci/archive/2009/03/01/257237.html上节说到我们有了一个线性分类函数,也有了…

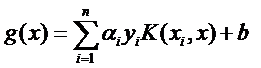
SVM入门(七)为何需要核函数
原文链接:
http://www.blogjava.net/zhenandaci/archive/2009/03/06/258288.html生存?还是毁灭?——哈姆雷特
可分?还是不可分?——支持向量机
之前一直在讨论的线性分类器,器如其名(汗,这是什么…
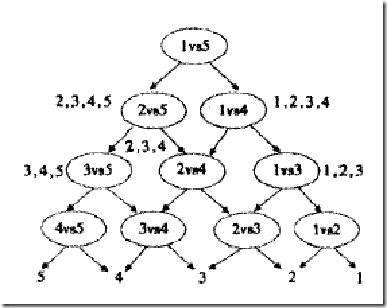
SVM入门(十)将SVM用于多类分类
原文地址:
http://www.blogjava.net/zhenandaci/archive/2009/03/26/262113.html从 SVM的那几张图可以看出来,SVM是一种典型的两类分类器,即它只回答属于正类还是负类的问题。而现实中要解决的问题,往往是多类的问题(少…
SVM入门(十一)SMO算法
原文链接:
http://www.cnblogs.com/jerrylead/archive/2011/03/18/1988419.html坐标上升法(Coordinate ascent)
在最后讨论的求解之前,我们先看看坐标上升法的基本原理。假设要求解下面的优化问题:这里W是向量的函数。…
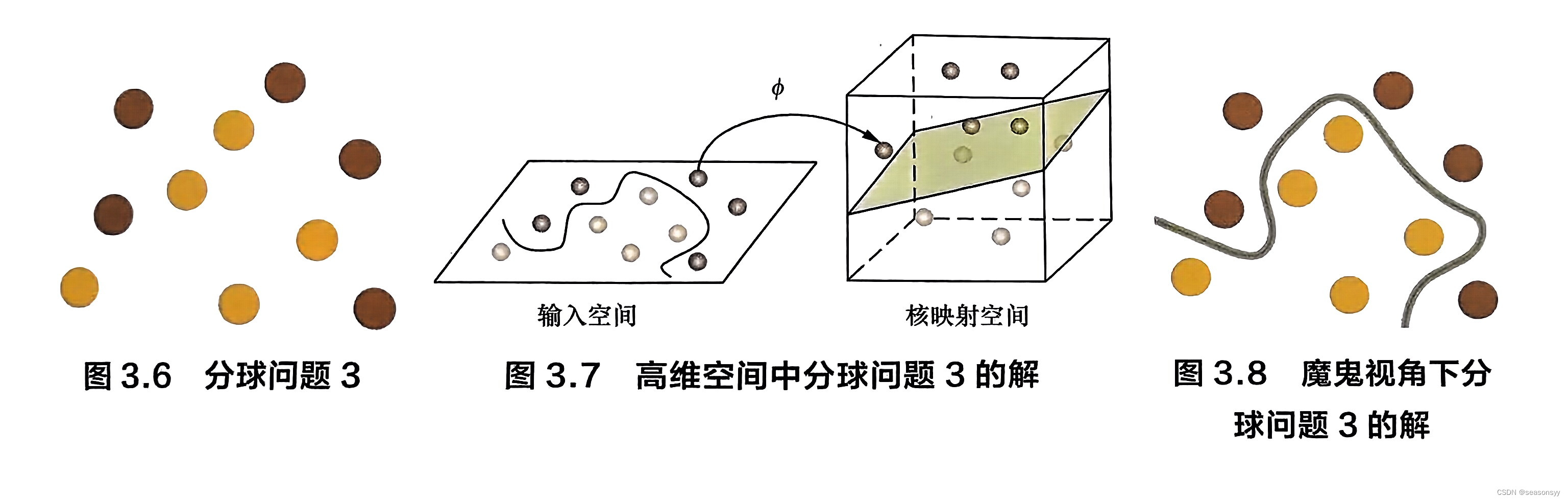
3.1 什么是支持向量机(SVM)?
3.1 什么是支持向量机(SVM)?
支持向量机(Support Vector Machine,SVM)是众多监督学习方法中十分出色的一种,几乎所有讲述经典机器学习方法的教材都会介绍。关于SVM,流传着一个关于天…
SVM(支持向量机)
搞懂间隔 给定训练样本集D{(x1,y1),(x2,y2),...,(xm,ym)},yi∈{−1,1}D{\{(x_{1},y_{1}),(x_{2},y_{2}),...,(x_{m},y_{m})\}},y_{i} \in \{-1,1\}D{(x1,y1),(x2,y2),...,(xm,ym)},yi∈{−1,1},分类学习最基本的想法就是基于训练集DDD在样本空间中找到…

凸优化学习(二)对偶和SVM
4.4 对偶问题
对于有约束的优化问题。约束优化问题的一般形式为: minimizesubject.tof0(x)fi(x)≤0fori1,2,...,mhi(x)0fori1,2,...,pminimizef0(x)subject.tofi(x)≤0fori1,2,...,mhi(x)0fori1,2,...,p\begin{array}
{l}
minimize & f_0(x)\\
subject. to &a…

机器学习算法---分类
当然,让我为您提供更详细的机器学习算法介绍,重点在于每种算法的原理、优缺点,并在注意事项中特别提到它们对非平衡数据和高维稀疏数据的适应性。
1. 决策树(Decision Trees)
原理: 决策树通过学习简单的…
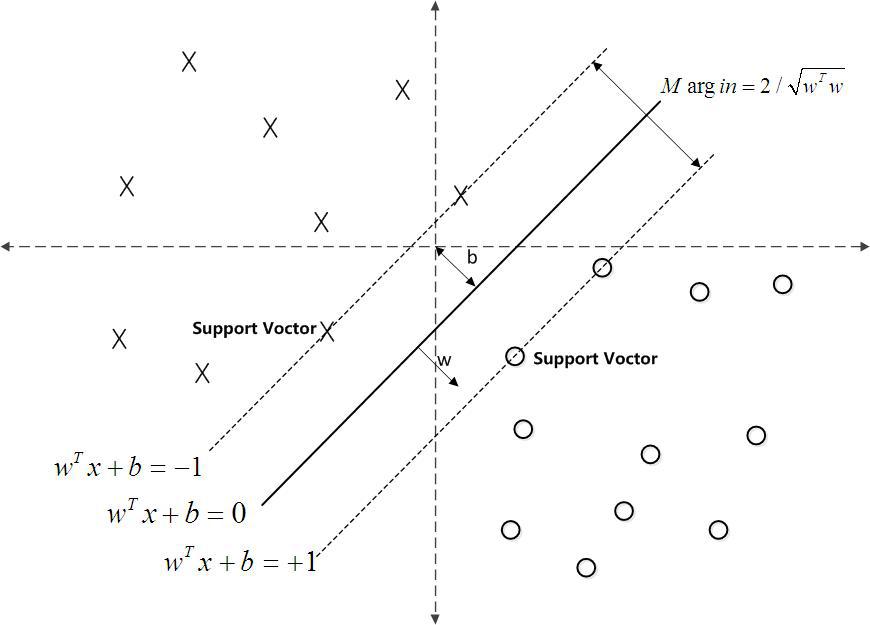
使用SVM实现iris花瓣预测
PCA降维单特征选择网格搜索
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline, FeatureUnion
from sklearn.model_sel…
支持向量机SVM简介
1. 定义及原理 SVM是一种二分类模型,是定义在特征空间上的间隔最大化(分离超平面)的线性分类器,(间隔最大使它有别于感知机)。
1.1 SVM适合处理什么样的数据?
适合小样本(非线性、高维模式)学习。高维稀疏、样本少&a…
线性SVM,线性可分SVM与核函数
SVM即支持向量机(support vector machine),是一种分类算法。SVM 适合中小型数据样本、非线性、高维的分类问题。它将实例的特征向量映射为空间中的一些点。如: 而SVM要做的事情就是找到那么一条线, “最好地” 区分这两…

机器学习十大算法之四:SVM(支持向量机)
SVM(支持向量机)
支持向量机(Support Vector Machine)是一种十分常见的分类器,曾经火爆十余年,分类能力强于NN,整体实力比肩LR与RF。核心思路是通过构造分割面将数据进行分离,寻找到一个超平面使样本分成两类,并且间隔…

要补税好几万,想卸载个税App了!
推荐:程序员简历怎么写才好?免费修改简历!!最近除了聊今天股票基金绿没绿之外,聊得最多的就是你个税自主申报了没有,退了多少税。听说身边也有不少小伙伴可以退税几百甚至几千的。好家伙,说得我…
【Machine Learning】Supervised Learning
本笔记基于清华大学《机器学习》的课程讲义监督学习相关部分,基本为笔者在考试前一两天所作的Cheat Sheet。内容较多,并不详细,主要作为复习和记忆的资料。 Linear Regression
Perceptron f ( x ) s i g n ( w ⊤ x b ) f(x)sign(w^\top x…
利用Hog特征和SVM分类器进行行人检测
之前介绍过Hog特征(http://blog.csdn.net/carson2005/article/details/7782726),也介绍过SVM分类器(http://blog.csdn.net/carson2005/article/details/6453502 );而本文的目的在于介绍利用Hog特征和SVM分类器来进行行人检测。 在…

用opencv自带hog实现行人检测)
本文主要介绍下opencv中怎样使用hog算法,因为在opencv中已经集成了hog这个类。其实使用起来是很简单的,从后面的代码就可以看出来。本文参考的资料为opencv自带的sample。 关于opencv中hog的源码分析,可以参考本人的另一篇博客:op…
学习OpenCV——Hog.detectMultiScale的心得
这几天一直为一个问题挠头,搞得好几天没心情,今天想明白了一点赶紧记下来,省的以后忘了。 这几天一直折磨我的问题就是Hog.detectMultiScale()函数。 我看到网上的有些HoG的文章从一幅完整图像中检测出目标对象时,一个很NB的框框&…

Ubuntu 14.04, 13.10 下安装 OpenCV 2.4.9
http://www.linuxidc.com/Linux/2014-12/110045.htm OpenCV(OpenCV的全称是:Open Source Computer Vision Library)是当今一个最受欢迎最先进的计算机视觉库,从许多非常简单的基本任务(图像数据的捕获和预处理…
OpenCV 3.0中的SVM训练 参数解析
opencv3.0和2.4的SVM接口有不同,基本可以按照以下的格式来执行: ml::SVM::Params params;
params.svmType ml::SVM::C_SVC;
params.kernelType ml::SVM::POLY;
params.gamma 3;
Ptr<ml::SVM> svm ml::SVM::create(params);
Mat trainData; // …

数据生成 | Matlab实现基于K-means和SVM的GMM高斯混合分布的数据生成
数据生成 | Matlab实现基于K-means和SVM的GMM高斯混合分布的数据生成 目录 数据生成 | Matlab实现基于K-means和SVM的GMM高斯混合分布的数据生成生成效果基本描述模型描述程序设计参考资料 生成效果 基本描述 1.Matlab实现基于K-means和SVM的GMM高斯混合分布的数据生成…
OpenCV--使用SVM
OpenCV3的接口变化挺大的,是原来OpenCV2.4.X版本的SVM不能用了,网上找了一下,找到了解决办法 SVM训练过程: 1, 注意其中训练和自动训练的接口,还有labelMat一定要用CV_32SC1的类型。
<code class"hljs lasso …
机器学习 | 一文看懂SVM算法从原理到实现全解析
目录
初识SVM算法
SVM算法原理
SVM损失函数
SVM的核方法
数字识别器(实操) 初识SVM算法
支持向量机(Support Vector Machine,SVM)是一种经典的监督学习算法,用于解决二分类和多分类问题。其核心思想是通过在特征空间中找到一…
台大林轩田支持向量机(SVM)完全解读
欢迎批评
机器学习之线性支持向量机
机器学习之对偶支持向量机
机器学习之核函数支持向量机
机器学习之软间隔支持向量机
机器学习之核函数逻辑回归
机器学习之支持向量机回归
最后感谢林轩田老师。
故障诊断 | 一文解决,SVM支持向量机的故障诊断(Matlab)
效果一览 文章概述 故障诊断 | 一文解决,SVM支持向量机的故障诊断(Matlab) 支持向量机(Support Vector Machine,SVM)是一种常用的监督学习算法,用于分类和回归分析。SVM的主要目标是找到一个最优的超平面(或者在非线性情况下是一个最优的超曲面),将不同类别的样本分开…

【Python机器学习】SVM——预处理数据
为了解决特征特征数量级差异过大,导致的模型过拟合问题,有一种方法就是对每个特征进行缩放,使其大致处于同一范围。核SVM常用的缩放方法是将所有的特征缩放到0和1之间。
“人工”处理方法: import matplotlib.pyplot as plt
from…

基于SVM的数据分类预测——意大利葡萄酒种类识别
update:把程序源码和数据集也附上http://download.csdn.net/detail/zjccoder/8832699
2015.6.24
---------------------------------------------------------------------------------------------------------------------------------------------------------…

梯度下降与支持向量机
前言 支持向量机解优化有两种形式,通常采用序列最小化(SMO)算法来解优化,本文总结基于随机梯度下降(SGD)解优化方法。
线性可分SVM 如果数据集是完全线性可分的,可以构造最大硬间隔的线性可分支…

libsvm中grid.py的使用
libsvm中有进行参数调优的工具grid.py和easy.py可以使用,这些工具可以帮助我们选择更好的参数,减少自己参数选优带来的烦扰。
所需工具:libsvm、gnuplot
本机环境:Windows7(64 bit) ,Python3.5
1、相关程序的下载和安装&#x…

支持向量机(support vector machine)
支持向量机SVM 支持向量机(support vector machine,SVM)是由Cortes和Vapnik在1995年提出的,由于其在文本分类和高维数据中强大的性能,很快就成为机器学习的主流技术,并直接掀起了“统计学习”在2000年前后的…

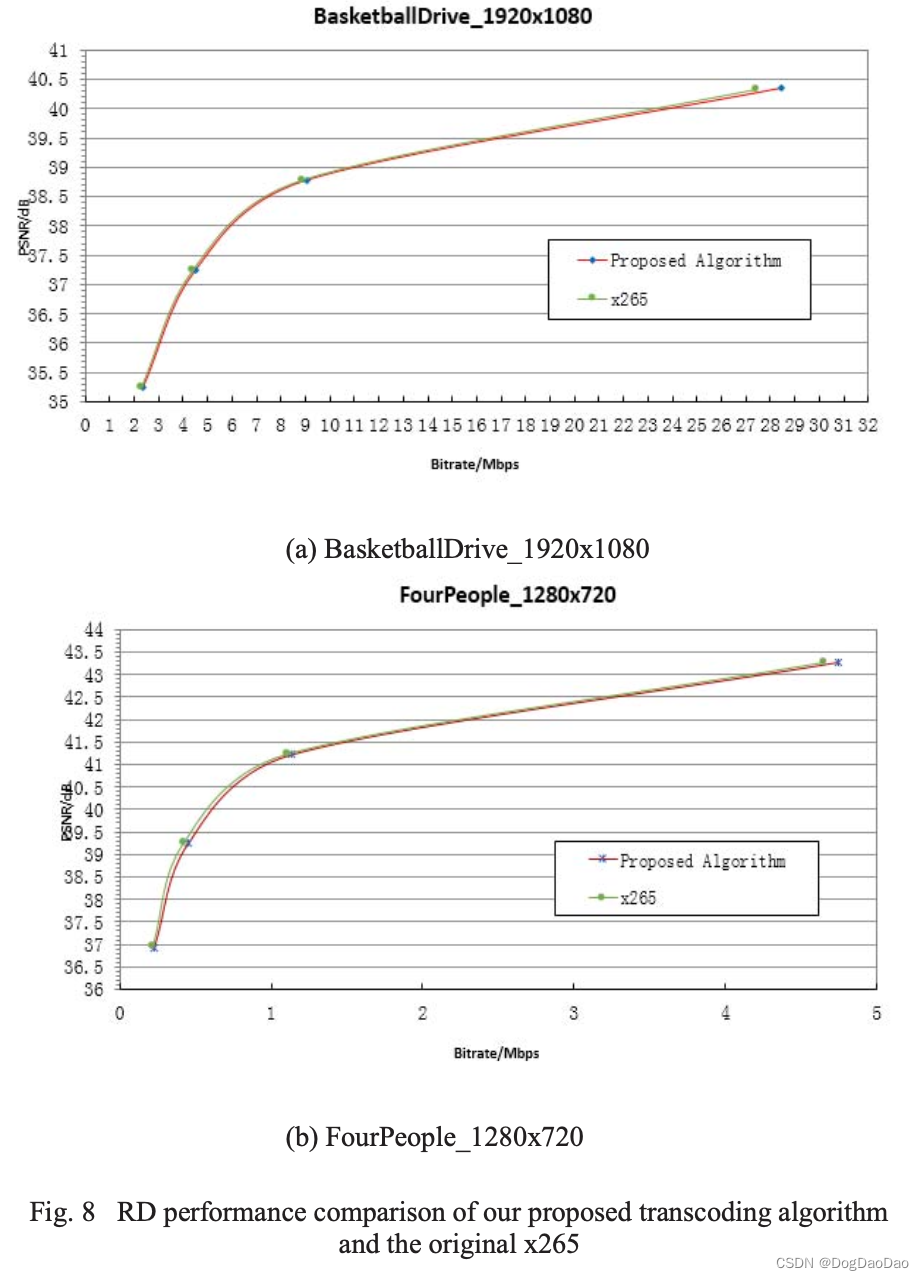
【论文解读】Learning based fast H.264 to H.265 transcoding
时间: 2015 年 级别: APSIPA 机构: 上海电力大学
摘要
新提出的视频编码标准HEVC (High Efficiency video coding)以其比H.264/AVC更好的编码效率,被工业界和学术界广泛接受和采用。在HEVC实现了约40%的编码效率提升的同时&…

机器学习算法---回归
1. 线性回归(Linear Regression)
原理: 通过拟合一个线性方程来预测连续响应变量。线性回归假设特征和响应变量之间存在线性关系,并通过最小化误差的平方和来优化模型。优点: 简单、直观,易于理解和实现。…
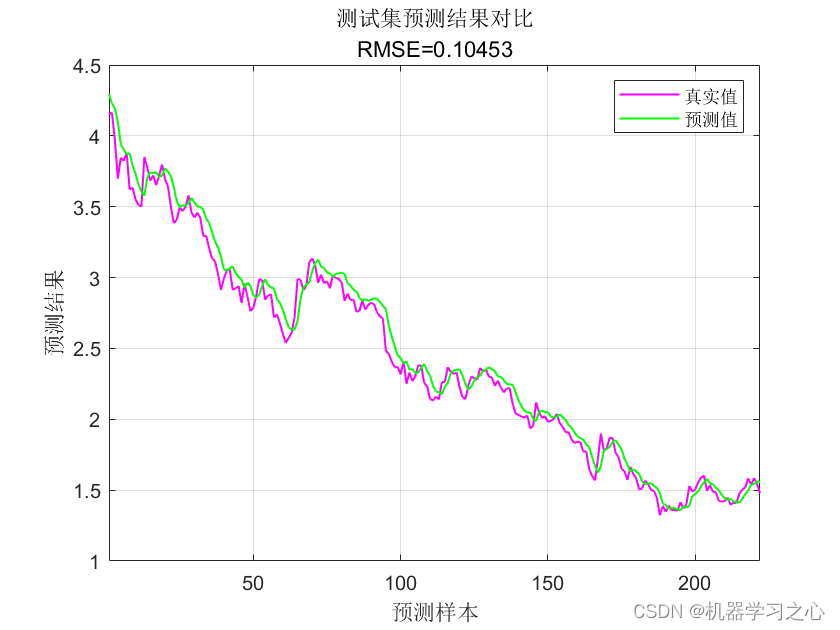
时序预测 | MATLAB实现DBN-SVM深度置信网络结合支持向量机时间序列预测(多指标评价)
时序预测 | MATLAB实现DBN-SVM深度置信网络结合支持向量机时间序列预测(多指标评价) 目录 时序预测 | MATLAB实现DBN-SVM深度置信网络结合支持向量机时间序列预测(多指标评价)效果一览基本描述程序设计参考资料 效果一览 基本描述 MATLAB实现DBN-SVM深度置信网络结合支持向量机…

使用Python实现SVM来解决二分类问题
下面是一个使用Python实现SVM来解决二分类问题的例子:
# 导入所需的库
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
import matplotlib.pyplot as plt# 生成一个二分类数据集
X, …
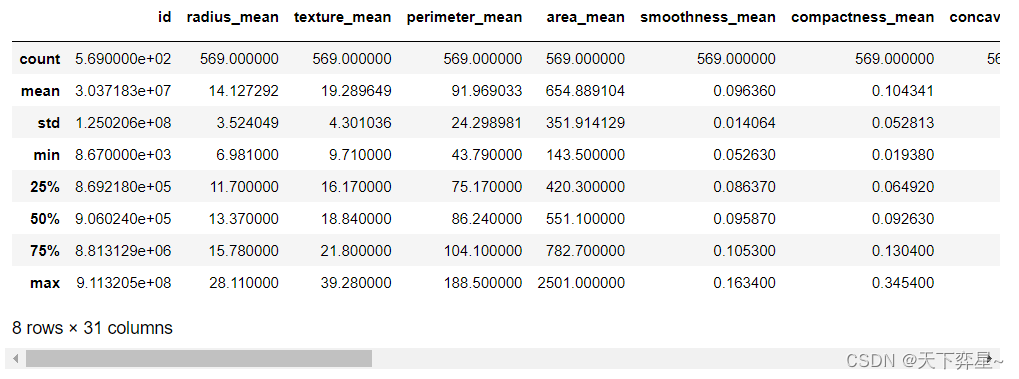
数据分析实战 | SVM算法——病例自动诊断分析
目录
一、数据分析及对象
二、目的及分析任务
三、方法及工具
四、数据读入
五、数据理解
六、数据准备
七、模型训练
八、模型应用及评价 一、数据分析及对象
CSV文件——“bc_data.csv”
数据集链接:https://download.csdn.net/download/m0_70452407/88…
SVM对噪声敏感原因
今天看西瓜书,然后看到习题关于 “SVM对噪声敏感原因”,看了几个答案,感觉不够系统,说的太细了,反而有种不太全面的感觉。我想了一下,大约应该是会
过拟合。因为SVM约束条件就是对于每个样本要正确分类&…

机器学习之软间隔支持向量机(机器学习技法)
为什么要软间隔SVM
硬边距SVM的过拟合
对于硬边距SVM产生过拟合的原因主要有两点:①我们选用的模型复杂度太高 ②我们坚持要将资料严格的分开。如下:从直觉来说Φ1虽然有一些犯错的地方但是它的模型复杂度较低不容易过拟合。我们不在执着于将资料严格分开…

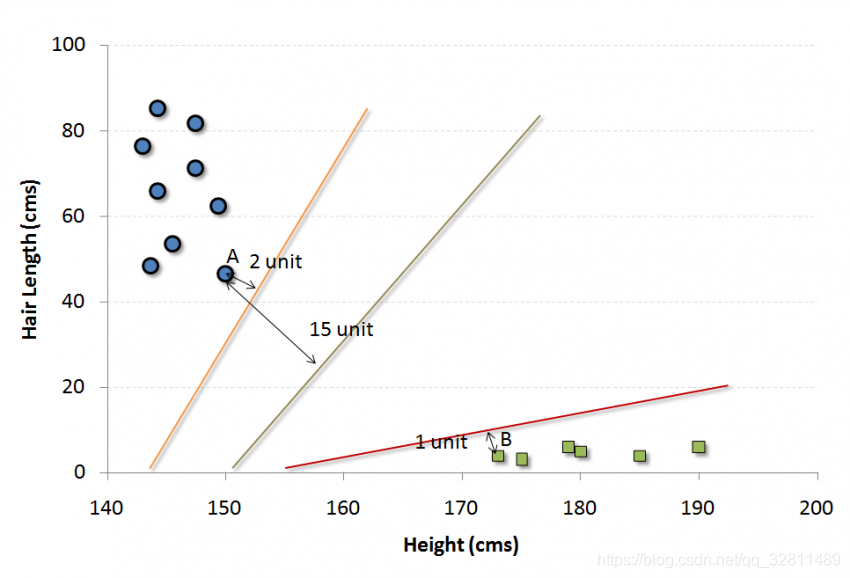
机器学习算法的基础(使用Python和R代码)之 SVM
4. SVM(支持向量机)
这是一种分类方法。在这个算法中,我们将每个数据项绘制为n维空间中的一个点(其中n是您拥有的特征的数量),每个特征的值是特定坐标的值。
例如,如果我们只有一个人的身高和头发长度这两个特征&…
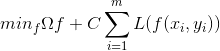
SVM支持向量机-软间隔与松弛因子(3)
上一篇文章推导SMO算法时,我们通过导入松弛因子,改变了对偶问题的约束条件,这里涉及到软间隔和正则化的问题,我们一直假定训练样本是完美无缺的,样本在样本空间或特征空间一定是线性可分的,即存在一个超平面…
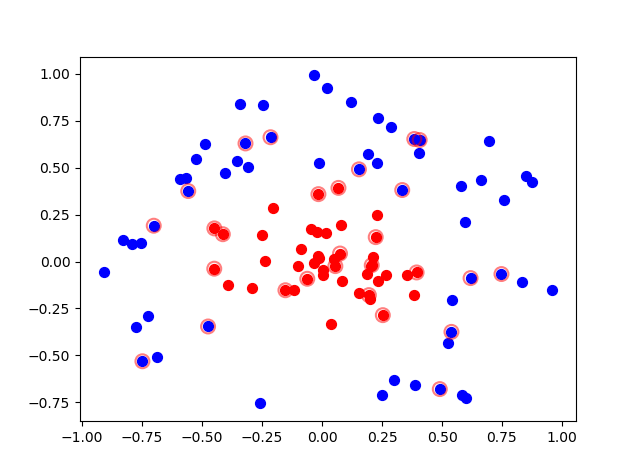
SVM支持向量机-核函数python实现(7)
数据可视化
上篇文章介绍了线性不可分和线性可分两种情况,以及五种核函数,线性核函数(linear),多项式核函数(poly),高斯核函数(rbf),拉普拉斯核函…

吹爆!遥感高光谱分类(Python)
目录 一、数据集下载
二、安装包
三、数据处理
四、模型训练
五、模型推理
六、踩坑记录 一、数据集下载
Hyperspectral Remote Sensing Scenes - Grupo de Inteligencia Computacional (GIC) (ehu.eus) Installing SPy — Spectral Python 0.21 documentation 二、安装…
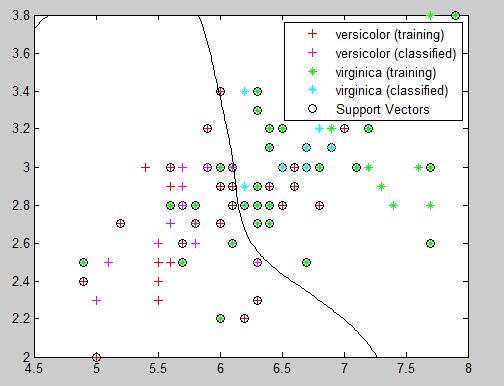
Matlab-SVM分类器
支持向量机(Support Vector Machine,SVM),可以完成对数据的分类,包括线性可分情况和线性不可分情况。 1、线性可分 首先,对于SVM来说,它用于二分类问题,也就是通过寻找一个分类线(二维是直线&…

SVM支持向量机-《机器学习实战》SMO算法Python实现(5)
经过前几篇文章的学习,SVM的优化目标,SMO算法的基本实现步骤,模型对应参数的选择,我们已经都有了一定的理解,结合《机器学习实战》,动手实践一个基本的SVM支持向量机,来完成一个简单的二分类任务…
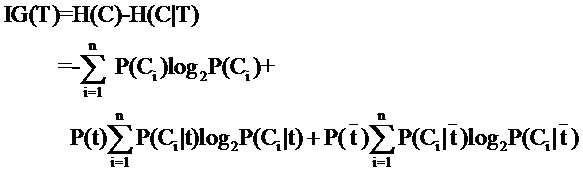

机器学习 支持向量机 --简单介绍
前言
我第一次听到“支持向量机”这个名字,我觉得,如果这个名字本身听起来那么复杂,那么这个概念的表述将超出我的理解范围。幸运的是,我看到了一些大学讲座视频,并意识到这个工具是多么简单有效。在本文中࿰…

A.机器学习入门算法(四): 基于支持向量机的分类预测
机器学习算法(四): 基于支持向量机的分类预测
本项目链接:https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc
1.相关流程
支持向量机(Support Vector Machine,SVM)是一个非常优雅的算法&a…

【神经网络学习笔记】上证指数开盘指数预测
摘要:
上证指数是反映上海证券交易所挂牌股票总体走势的统计指标。上海证券交易所股票指数的发布几乎是和股市行情的变化相同步的,它是我国股民和证券从业人员研判股票价格变化趋势必不可少的参考依据。本文通过分析1991年至今近6000个交易日的开盘指数…
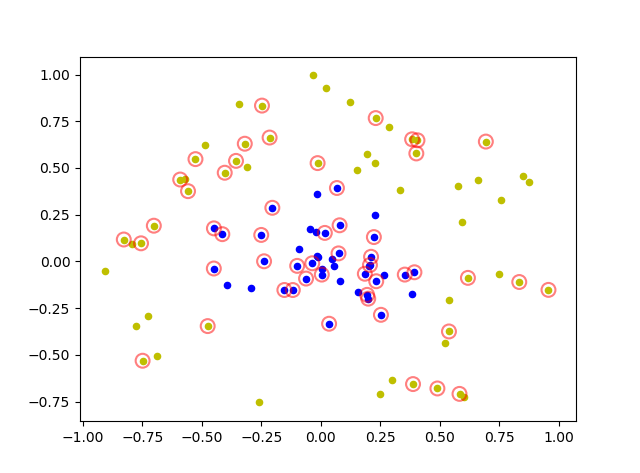
SVM支持向量机-SKlearn实现与绘图(8)
了解了SVM的基本形式与算法实现,接下来用SKlearn实现支持向量机分类器.
1.函数定义与参数含义
先看一下SVM函数的完全形式和各参数含义:
SVC(C1.0, kernel’rbf’, degree3, gamma’auto’, coef00.0, shrinkingTrue, probabilityFalse, tol0.001, ca…
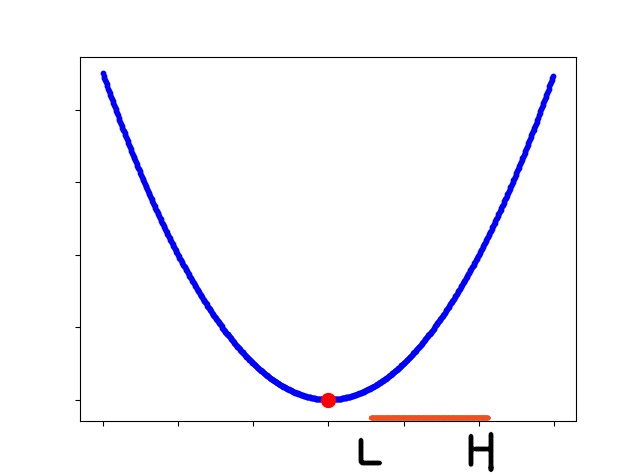
SVM支持向量机-Alpha范围界定与调整(4)
SVM支持向量机-SMO算法推导(2)一文中我们写到了α2的范围选择,这里单独解释一下L,H的计算,和α2的调整规则。 1.范围限定
先看一下SMO算法推导那篇文章中α2的范围: 依据简化约束,我们需要分两种情况讨论(其实是四种&…
SVM多分类问题 libsvm在matlab中的应用
对于支持向量机,其是一个二类分类器,但是对于多分类,SVM也可以实现。主要方法就是训练多个二类分类器。 一、多分类方式 1、一对所有(One-Versus-All OVA) 给定m个类,需要训练m个二类分类器。其中的分类…
深度学习与计算机视觉系列(3)_线性SVM与SoftMax分类器
作者: 寒小阳 &&龙心尘 时间:2015年11月。 出处: http://blog.csdn.net/han_xiaoyang/article/details/49949535 http://blog.csdn.net/longxinchen_ml/article/details/50001979 声明:版权所有,转载请注…
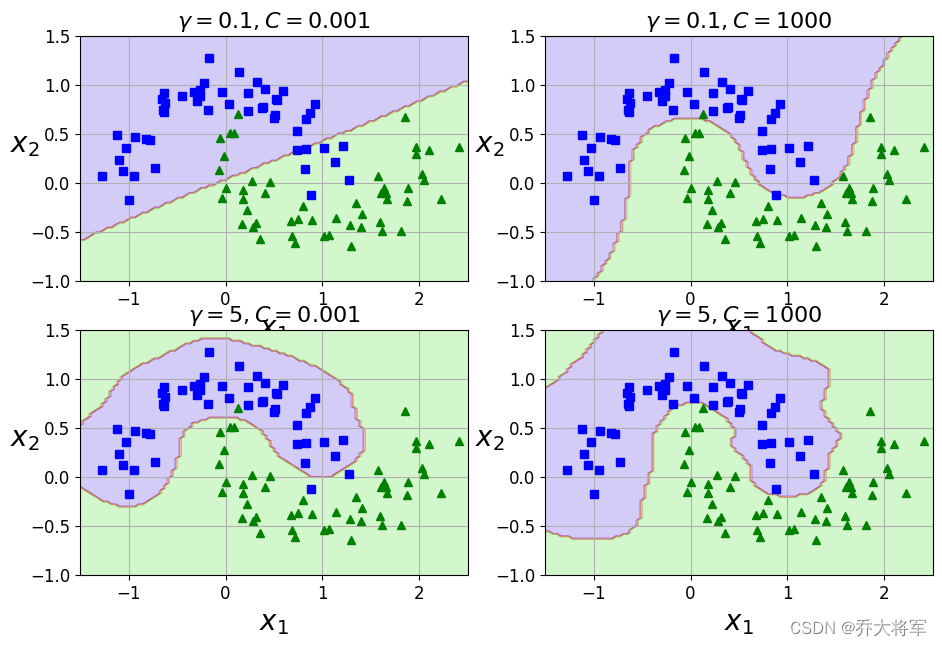
SVM-支持向量机实验分析(软硬间隔,线性核,高斯核)
目录 一、前言
二、实验 0. 导入包 1. 支持向量机带来的效果 2. 软硬间隔 3. 非线性支持向量机 4. 核函数变换 线性核 高斯核 对比不同的gamma值对结果的影响 一、前言 学习本文之前要具有SVM支持向量机的理论知识,可以参考支持向量机(Support Vector …

SVM/LDM 中的一个优美的证明(个人觉得)
前言:
在读周志华的Large Margin Distribution Machine一文时看到的。 下面先简单回顾SVM,然后直接讲LDM,接着说看到的那个证明。其实也没啥。。 一言以蔽之,给定IID分布训练集S,SVM的假设函数是一个线性模型f(x)w T…

机器学习经典算法之SVM深入解析
前言
起初让我最头疼的是拉格朗日对偶和SMO,后来逐渐明白拉格朗日对偶的重要作用是将w的计算提前并消除w,使得优化函数变为拉格朗日乘子的单一参数优化问题。而SMO里面迭代公式的推导也着实让我花费了不少时间。
对比这么复杂的推导过程,SV…

机器学习100天(四十):040 线性支持向量机-公式推导
《机器学习100天》完整目录:目录 机器学习 100 天,今天讲的是:线性支持向量机-公式推导!
首先来看这样一个问题,在二维平面上需要找到一条直线划分正类和负类。 我们找到了 A、B、C 三条直线。这三条直线都能正确分类所有训练样本。但是,哪条直线最好呢?直观上来看,我…
MATLAB 调用LIBSVM 进行分类任务
LIBSVM是台湾大学林智仁(Lin Chih-Jen)教授等开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包,他不但提供了编译好的可在Windows系列系统的执行文件,还提供了源代码,方便改进、修改以及在其它操作系统上应用;…
![深度学习与计算机视觉[CS231N] 学习笔记(3.1):损失函数(Loss Function)](https://img-blog.csdn.net/20180110163658691?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQva3N3czAyOTI3NTY=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)
深度学习与计算机视觉[CS231N] 学习笔记(3.1):损失函数(Loss Function)
在上一节的线性回归的例子中,我们通过一定的矩阵运算获得了每张图像的最终得分(如下图),可以看到,这些得分有些是比较好的预测,有些是比较差的预测,那么,具体如何定义“好”与“差”…
机器学习(6):支持向量机(SVM)
最近自己会把自己个人博客中的文章陆陆续续的复制到CSDN上来,欢迎大家关注我的 个人博客,以及我的github。
本文将讲解有关支持向量机(SVM)的有关知识,主要包括线性可分SVM,线性SVM和非线性SVM的相关原理和…

浙江大学利用 SVM 优化触觉传感器,盲文识别率达 96.12%
生物传感是人类与机器、人类与环境、机器与环境交互的重要媒介。其中,触觉能够实现精准的环境感知,帮助使用者与复杂环境交互。 为模仿人类的触觉,科研人员开发了各种传感器,以模拟皮肤对环境的感知。然而,触觉传感的要…
机器学习中的算法(2)-支持向量机(SVM)基础
原文地址为:
机器学习中的算法(2)-支持向量机(SVM)基础版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleastgmail.com。也…


【机器学习】支持向量机SVM原理及推导
参考:http://blog.csdn.net/ajianyingxiaoqinghan/article/details/72897399 部分图片来自于上面博客。
0 由来 在二分类问题中,我们可以计算数据代入模型后得到的结果,如果这个结果有明显的区别,这就说明模型可以把数据分开。那…

SVM from another perspective
This article records my process of study.Link:SVM.There are not Lagrange and KKT condition.Here,we mainly use gradient descent. Binary Classification
Because g(x)g(x)g(x) only outputs 111 or −1-1−1.Thus δ\deltaδ can’t use gradient descent.We use anot…
葫芦书笔记----经典算法
经典算法
SVM
在空间中线性可分的两类点,分别向SVM分类的超平面做投影,这些点在超平面上的投影仍然是线性可分的吗?
速记:不是
详细:一个简单的反例:设二维空间中只有两个样本点,每个点各属…

机器学习-白板推导-系列(六)笔记:SVM
文章目录0 笔记说明1 硬间隔SVM1.1 模型定义1.2 对偶问题1.3 KKT条件1.4 最终模型2 软间隔SVM3 约束优化问题3.1 弱对偶性证明3.2 对偶关系之几何解释3.3 对偶关系之slater条件3.4 对偶关系之KKT条件3.4.1 可行条件3.4.2 互补松弛条件3.4.3 梯度为04 Kernel SVM0 笔记说明
来源…
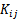
核函数径向基核函数 (Radial Basis Function)--RBF
1.核函数 1.1核函数的由来 -----------还记得为何要选用核函数么?----------- 对于这个问题,在Jaspers Java Jacal博客《SVM入门(七)为何需要核函数》中做了很详细的阐述,另外博主对于SVM德入门学习也是做了很详细的阐…

分类预测 | MATLAB实现SSA-FS-SVM麻雀算法同步优化特征选择结合支持向量机分类预测
分类预测 | MATLAB实现SSA-FS-SVM麻雀算法同步优化特征选择结合支持向量机分类预测 目录 分类预测 | MATLAB实现SSA-FS-SVM麻雀算法同步优化特征选择结合支持向量机分类预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 MATLAB实现SSA-FS-SVM麻雀算法同步优化特征选择结…

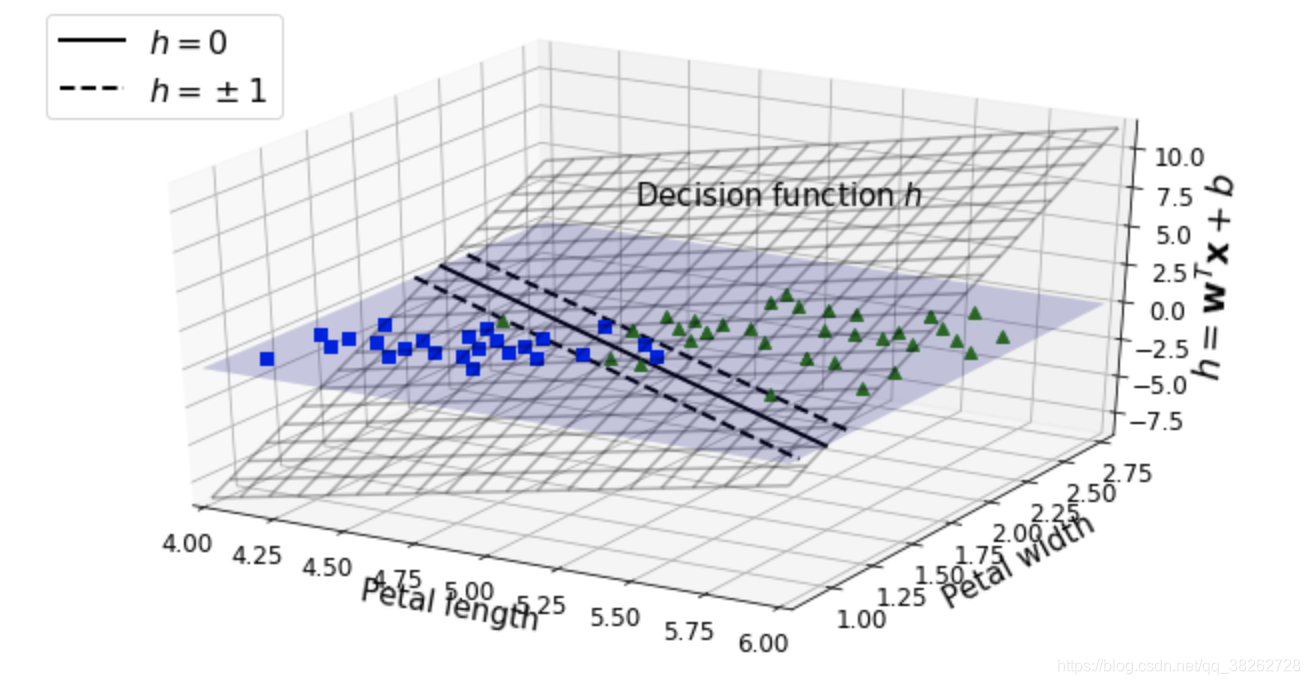
SVM支持向量机-拉格朗日乘子与对偶问题(1)
对于支持向量机,我们首先要关注的几个点就是间隔,超平面,支持向量,再深入的话就是对偶问题,拉格朗日对偶问题,凸优化,和 KKT条件,我们先从基本的间隔,超平面,…
机器学习之svm---车牌识别
目标团队 承接嵌入式linux软硬件开发、机器视觉 图像处理、网络流等项目微信号:hgz1173136060本文档尝试解答如下问题:如何使用OpenCV函数 CvSVM::train 训练一个SVM分类器, 以及用 CvSVM::predict 测试训练结果。一、简单介绍与opencv的使用什么是支持向…

分类预测 | Matlab特征分类预测全家桶(BP/SVM/ELM/RF/LSTM/BiLSTM/GRU/CNN)
分类预测 | Matlab特征分类预测全家桶(BP/SVM/ELM/RF/LSTM/BiLSTM/GRU/CNN) 目录 分类预测 | Matlab特征分类预测全家桶(BP/SVM/ELM/RF/LSTM/BiLSTM/GRU/CNN)预测效果基本介绍程序设计参考资料致谢 预测效果 基本介绍 分类预测 | …
机器学习实战——基于Scikit-Learn和TensorFlow 阅读笔记 之 第五章:支持向量机
《机器学习实战——基于Scikit-Learn和TensorFlow》 这是一本非常好的机器学习和深度学习入门书,既有基本理论讲解,也有实战代码示例。 我将认真阅读此书,并为每一章内容做一个知识笔记。 我会摘录一些原书中的关键语句和代码,若有…
OpenCV-Python官方教程-30- 支持向量机(support vector machines, SVM)
使用SVM进行手写数据OCR
在 kNN 中我们直接使用像素的灰度值作为特征向量。这次我们要使用方向梯度直方图Histogram of Oriented Gradients (HOG)作为特征向量。
在计算 HOG 前我们使用图片的二阶矩对其进行抗扭斜(deskew)处理&…
故障诊断模型 | Maltab实现SVM支持向量机的故障诊断
效果一览 文章概述 故障诊断模型 | Maltab实现SVM支持向量机的故障诊断 模型描述
Chinese: Options:可用的选项即表示的涵义如下 -s svm类型:SVM设置类型(默认0) 0 – C-SVC 1 --v-SVC 2 – 一类SVM 3 – e -SVR 4 – v-SVR -t 核函数类型:核函…

机器学习实战:SVM支持向量机
一、支持向量机理解:
《机器学习实战》里面对SVM原理一笔带过,SMO算法也没详细讲,可以先看看下面的资料
SVM的公式不好理解,我花了2周,看完《机器学习》的SVM章节还是不太懂,
参考:支持向量机…
使用sklearn简单进行SVM参数优选
SVM简单回顾
支持向量机(SVM)方法建立在统计学VC维和结构风险最小化原则上,试图寻找到一个具有最大分类间隔的超平面,支持向量(Support Vector)是支持向量机训练的结果,在进行分类或者回归时也…

SMO(序列最小优化算法)解析
什么是SVM
SVM是Support Vector Machine(支持向量机)的英文缩写,是上世纪九十年代兴起的一种机器学习算法,在目前神经网络大行其道的情况下依然保持着生命力。有人说现在是神经网络深度学习的时代了,AI从业者可以不用…

SVM拓展和SVR支持向量回归
软间隔
在建立SVM模型时,假定正负样本是线性可分的。但是,实际有些时候,样本不是完全线性可分的,会出现交错的情况,例如下图。 这时,如果采用以下模型 minw,b{12∥w∥22},subject toyi(wTxib)≥1minw,b{12…

支持向量机SVM浅析(待补充)
先发一张个人对svm的主要概念图:
1. 几何间隔与支持向量 对于用于分类的支持向量机,它是个二分类的分类模型。也就是说,给定一个包含正例和反例(正样本点和负样本点)的样本集合,支持向量机的目的就是基于…

5003笔记 Statistic Chapter5-Introduction to classification techniques(LR LDA KNN SVM)
p是指分到1的概率,1-p就是分到0的概率。所以Odd ratio就是分到1的概率占分到0的概率的多少倍。Log Odd ratio是一个线性函数,就是线性回归的y。 fk(x) P(xx|yk),f(x)就是一个概率密度函数。 σ2是方差,我们假设每个K类…
【KKT】∇f(x)+λ∇g(x)=0中λ的讨论
Karush-Kuhn-Tucker (KKT)条件 〇、问题背景
在阅读 Karush-Kuhn-Tucker (KKT)条件 时,不太能理解 ∇ f \nabla f ∇f 的方向,以及 ∇ g \nabla g ∇g 的方向: 为什么 ∇ f \nabla f ∇f 是指向可行域内部, ∇ g \nabla g ∇g…

【文本分类】基于两种分类器实现影评的情感分析(SVM,KNN)
支持向量机(Support Vector Machine, SVM)
当线性不可分时,就进行升维;接着就可以使用线性分类器了理论上来说,对任何分类问题,SVM都可以通过选择合适的核函数来完成核函数的选择直接影响到 SV…
cs231n assignment1 SVM vectorize梯度矩阵傻瓜式推导
梯度矩阵dW的vectorize实现
这个向量化实现想了很久,一直看不懂代码,别人的博客也没解释具体为什么会是那样实现的,尤其是为什么最后是X去乘上一个矩阵得到梯度矩阵,看得我一脸懵逼,最后我自己画了个2*3的矩阵才终于知…
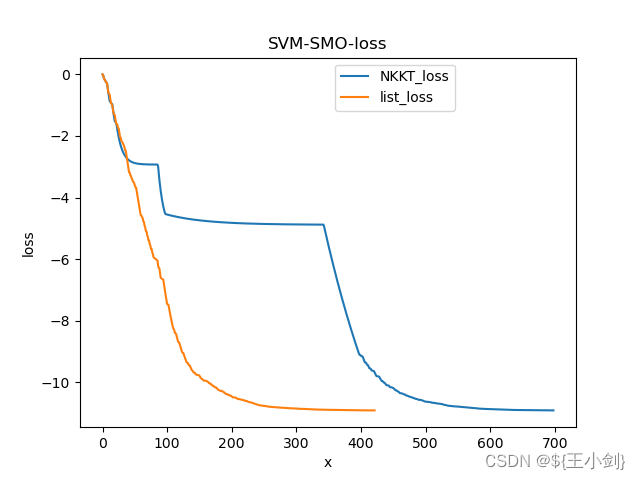
SVM支持向量机理解_KKT条件_拉格朗日对偶_SMO算法代码
目录
一、支持向量机基本型(线性可分)
1.1 问题描述
1.2 参考资料
二、KKT条件
2.1 KKT条件的几个部分
2.1.1 原始条件
2.1.2 梯度条件
2.1.3 松弛互补条件
2.1.4 KKT条件小结
2.2 参考资料
三、对偶形式
3.1 由原始问题到对偶问题
3.2 对偶…
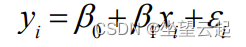
异常检测学习笔记 三、线性回归方法、主成分分析、支持向量机
一、线性回归方法 类似这样的函数是线性回归模型和支持向量机的基础,线性函数很简单,如果原始问题是非线性的,那么将其转化为线性问题更容易处理,比如下面的方程。 线性映射是主成分分析的重要组成部分。 寻找响应(因变量)和解释变量(自变量)之间的线性关系,…

机器学习读书笔记之7 - 分类方法梳理
在提取特征以后,如何根据这些特征判断,称之为分类,解决分类问题的方法很多,常用分类方法主要包括:KNN、支持向量机(SVM)、贝叶斯、决策树、人工神经网络等;另外还有用于组合单一分类…
sklearn.svm.SVC 支持向量机-简介
sklearn.svm.SVC 是 Scikit-learn(一个常用的机器学习库)中的一个类,用于支持向量机(Support Vector Machine,SVM)算法中的分类任务。
SVM 是一种用于分类和回归的监督学习算法。在分类任务中,…
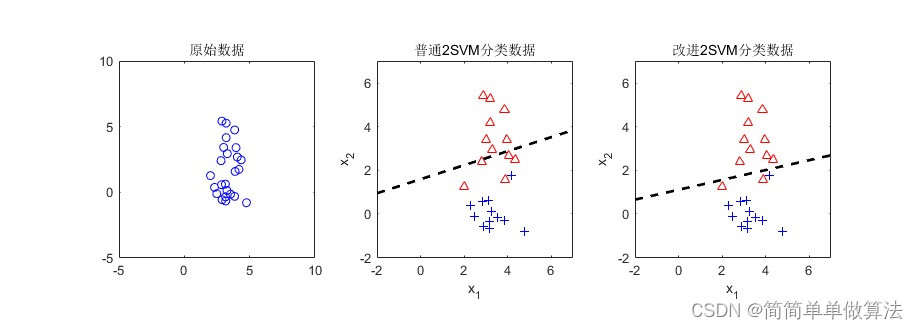
基于自适应支持向量机的matlab建模与仿真,不使用matlab的SVM工具箱函数
目录
1.算法运行效果图预览
2.算法运行软件版本
3.部分核心程序
4.算法理论概述
5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本
matlab2022a
3.部分核心程序
............................................................
figure;
subplot(131);
for …

机器学习技法笔记01-----线性SVM支持向量机
写的文章发给老师看得到回复里面有:去看看机器学习基础知识~ Fine,最近,来一波机器学习基础~ 机器学习技法主要介绍特征转换(Feature Transforms)的三个方向: 1)Embeddin…
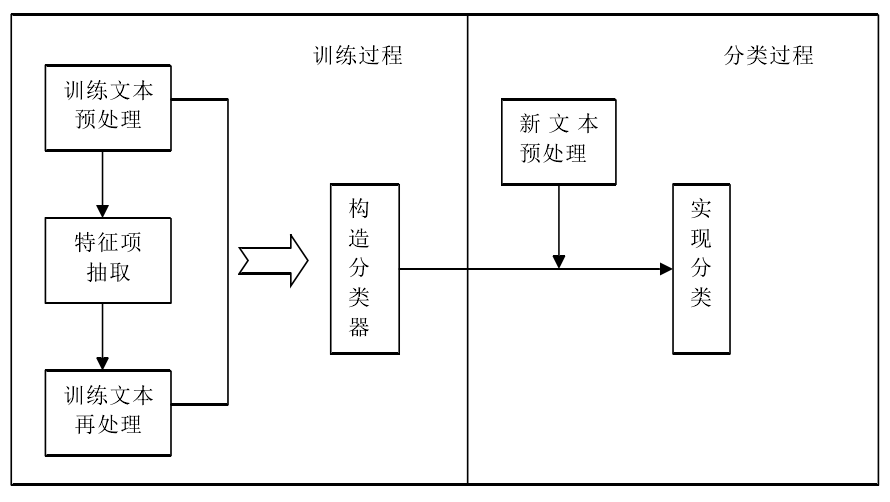
基于支持向量机SVM的文本分类的实现
基于支持向量机SVM的文本分类的实现
1 SVM简介 支持向量机(SVM)算法被认为是文本分类中效果较为优秀的一种方法,它是一种建立在统计学习理论基础上的机器学习方法。该算法基于结构风险最小化原理,将数据集合压缩到支持向量集合&a…

基于Python和Opencv的目标检测与特征
1.目标检测 (1)什么是目标检测? 判断一副图像或者视频的一帧存不存在目标物体,例如检测一幅图片中有没有花,有 没有人脸,或者检测一段视频中行驶过的车辆、行人等 检测完成后,也可以继续往深做目标识别,例如…

SVM支持向量机-SMO算法公式推导(2)
1.SMO算法简介
SMO算法又称序列最小优化,是John Platt发布的的一种训练SVM的强大算法,SMO算法的思想是将大的优化问题转换为多个小优化问题,这些小的优化往往很容易求解,并且对他们进行顺序求解和作为整体求解的结果是完全一致的…

论文学习——基于LSTM神经网络的畸形波预测
文章目录0 封面1 标题2 摘要3 结语4 *启示5 引言6 实验设计写在前面:《华中科技大学学报(自然科学版)》;主办单位:华中科技大学;中文核心;双月报;
0 封面 1 标题
基于LSTM神经网络…

基于MATLAB,运用PCA+SVM的特征脸方法人脸识别
简介: 这是楼主的第一篇博客文章,下决心写博客也是希望大家在相互交流中得到进步,楼主重大研一学生,菜鸟一名,我希望从一个菜鸟的角度出发来看待一些问题的解决,很多东西也都是针对初学者而言的。文章中可能…
机器学习算法中文视频教程
机器学习算法中文视频教程 在网上狂搜ReproducingKernel Hilbert Space的时候,找到了一个好东西。这个是李政軒Cheng-Hsuan Li的关于机器学习一些算法的中文视频教程。感觉讲得很好。这里非常感谢他的分享:http://www.powercam.cc/chli。也贴到这里&…
OpenCv3.0+SVM的使用心得(二)
主要有4点总结: 1. 读取txt的内容(文件路径),按行输出。下面语句中,pictures.txt中是文件夹中的文件(图片)列表,samplePath是文件夹路径(string格式)。string和char类型可以使用‘…

LIBSVM与LIBLINEAR
原文链接:
http://blog.chinaunix.net/uid-20761674-id-4840097.html
在过去的十几年里,支持向量机(Support Vector Machines)应该算得上是机器学习领域影响力最大的算法了。而在SVM算法的各种实现工具中,由国立台湾大…

基于opencv的SVM算法的车牌识别系统设计与实现
基于opencv的SVM算法的车牌识别系统设计与实现
车牌识别技术是智能交通系统中的一项关键技术,它能够自动识别车辆的车牌号码。本文将详细介绍如何使用Python编程语言结合OpenCV库和SVM算法来实现车牌识别系统。
系统架构
车牌识别系统主要包括以下几个模块&…

liblinear使用说明
Liblinear是一个简单的解决大规模线性化分类和回归问题的软件包。它目前支持: -L2正则化逻辑回归/L2损失支持向量分类/L1损失支持向量分类法 -L1正则化L2损失支持向量分类/L1正则化逻辑回归 -L2正则化L2损失支持向量回归/L1损失支持向量回归。 这篇文献介绍了Liblinear的用法。…

机器学习:完全线性可分/近似线性可分/非线性可分的支持向量机
文章目录0 前言1 完全线性可分支持向量机1.1 模型的数学形式1.2 模型的评价策略1.3 模型的优化方法2 近似线性可分支持向量机2.1 支持向量2.2 合页损失函数3 非线性可分的支持向量机3.1 非线性分类问题3.2 核函数的定义3.3 核技巧在支持向量机中的应用3.4 正定核3.5 常见核函数…
OpenCV-Python(47):支持向量机
原理
线性数据分割 如下图所示,其中含有两类数据,红的和蓝的。如果是使用kNN算法,对于一个测试数据我们要测量它到每一个样本的距离,从而根据最近的邻居分类。测量所有的距离需要足够的时间,并且需要大量的内存存储训…